All-Access Membership
About Course
The field of bioinformatics is rapidly growing and offers numerous opportunities for students to advance their knowledge and skills. With the help of BioCode, students can have access to the latest advancements in bioinformatics and become more competitive in the global job market, ultimately contributing to the growth and development of the field.
With BioCode’s All-access membership plan, students will have complete access to every bioinformatics course on the website, empowering them to learn about the latest advancements in this rapidly growing field. The All-access membership plan offers students a plethora of benefits, including unlimited access to all courses, personalized learning paths, and interactive tools and resources that make learning more engaging and effective.
As an All-access member, students will have complete access to every course on the BioCode website. This includes foundational courses that cover the basics of bioinformatics, as well as advanced courses that explore cutting-edge topics such as machine learning and single-cell genomics. With unlimited access to all courses, students can learn at their own pace and customize their learning experience to suit their needs.
BioCode’s All-access membership plan offers students personalized learning paths based on their interests and skill level. Students can take a self-assessment to identify their strengths and weaknesses, and then receive recommendations for courses that will help them achieve their goals. This personalized approach to learning ensures that students get the most out of their membership and can advance their knowledge of bioinformatics quickly and efficiently.
BioCode’s All-access membership plan also includes 24/7 support from expert bioinformatics instructors. Students can ask questions, receive feedback on their work, and get personalized guidance on their learning journey. This level of support ensures that students always have the resources they need to succeed in their studies.
Overall, BioCode’s All-access membership plan is an excellent choice for students who want to expand their knowledge of bioinformatics and stay up-to-date on the latest advancements in the field. With unlimited access to all courses, personalized learning paths, interactive tools and resources, and 24/7 support, students can achieve their goals quickly and efficiently.
Mentioned below are some of the important sections of this membership plan:
Section 1: Bioinformatics Databases
Description: This section will focus on making sure that the students gain an understanding of the various bioinformatics databases that are used frequently during biological data analysis. Students will also learn about the structure and content of bioinformatics databases, including the types of data stored, the format of the data, and the tools and interfaces used to access and analyze the data. This section covers popular databases such as NCBI, BLAST, and GenBank, and how to search and retrieve data from these databases using various search methods and filters.
Learning Outcomes: Upon completion of this section, students will be able to:
- Discuss NCBI.
- Perform Sequence Analysis.
- Describe GenBank.
- Discuss Gene Database.
- Explain RefSeq Database.
- Discuss BLAST Database Searching.
- Describe the Molecular Modelling Database.
- Explain the Short Genetic Variations Database (dbSNP).
- Discuss Homologene.
- Explain Taxonomy.
- Describe UCSC Genome Browser.
- Discuss Table Browser.
- Explain ENSEMBL.
- Perform Genome Assembly Retrieval and Analysis.
- Perform Gene Analysis & Annotation.
- Describe Variation Analysis.
- Interpret Plant Genome Records
- Visualize a Plant Genome Using JBrowse
- Explain Gene Reference Consortium.
- Describe Sequence Read Archive.
- Discuss BioProject, BioSystem, and BioSample.
- Explain Gene Expression Omnibus Database.
Section 2: Bioinformatics File Formats
Description: This section will focus on making sure that the students gain an understanding of the various bioinformatics databases that are used frequently during biological data analysis and their importance in storing and sharing biological data. This section provides an overview of file formats such as FASTA, FASTQ, SAM/BAM, VCF, GFF/GTF, and BED, and their specific uses in different areas of bioinformatics, such as sequence analysis, alignment, variant calling, and genome annotation.
Learning Outcomes: Upon completion of this section, students will be able to:
- Explain FASTA (Sequence Format).
- Discuss GenBank (Sequence Annotation Format).
- Describe FASTQ Format.
- Explain Gene File Format/Gene Transfer Format.
- Describe BED (Gene Structure Format).
- Discuss SAM.
- Discuss BAM.
- Explain Clustal Omega Alignment Format.
- Describe MEGA (Alignment Format).
- Explain PHYLIP – Multiple Sequence Alignment Format.
- Explain Stockholm Alignment Format.
Section 3: Protein Databases and Analysis
Description: This section will make sure students learn about the different types of protein databases and their role in protein research and analysis. This section provides an overview of popular protein databases such as UniProt, PDB, and InterPro, and how to search and retrieve protein data from these databases using various search methods and filters.
Learning Outcomes: Upon completion of this section, students will be able to:
- Explain UniProt Database and Protein Analysis.
- Discuss UniProt BLAST.
- Describe Protein Data Bank (PDB).
- Perform Alignment Between Two PDB Sequences & Structures
- 3D Structure Visualization on PDB.
- Calculate the Mapping Genomic Position to Protein Sequence and 3D Structure
- Evaluate Genomic Discovery of Protein Structure Through Gene.
- Discuss HMMER.
- Desribe SignalP & TargetP.
- Explain Pfam.
- Describe PROSITE.
- Discuss ScanProsite.
- Describe Marcoil.
- Explain SMART 6.
Section 4: Sequence Alignment and Analysis
Description: This section will make sure students will learn about the principles and methods of sequence alignment, a fundamental tool in bioinformatics used to compare two or more sequences of DNA, RNA, or proteins. This section covers different types of sequence alignment methods, including pairwise alignment and multiple sequence alignment, and the algorithms used to perform these alignments. The section covers the tools and techniques used for sequence alignment and analysis, including BLAST, ClustalW, and MUSCLE, and how to interpret and analyze the results of sequence alignments.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Global Alignment of Sequences Using EMBOSS NEEDLE.
- Perform Multiple Sequence Alignment Using Clustal Omega.
- Perform Sequence Alignment Using EMBOSS Water.
- Perform Sequence Alignment Using Jalview.
- Perform Iterative Multiple Sequence Alignment Using T-Coffee.
- Perform Accurate Multiple Sequence Alignment Using MUSCLE.
- Perform Multiple Sequence Alignment Using MEGA.
- Perform Multiple Sequence Alignment Using MAFFT.
- Perform Multiple Sequence Alignment Using MAFFT Aln2Plot.
Section 5: Phylogenetic Analysis
Description: This section will make sure students will learn about the tools and techniques used for phylogenetic analysis. The section covers the interpretation and analysis of phylogenetic trees, including branch lengths, node support, and tree topology.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Phylogenetic Analysis Using MEGA.
- Perform Phylogenetic Analysis Using iTOL.
- Perform Phylogenetic Analysis Using FigTree.
Section 6: Secondary Structure Prediction
Description: This section will make sure students will learn about the principles and methods of predicting the secondary structure of proteins from their amino acid sequences. This section covers the importance of protein secondary structure in protein function, stability, and folding, and how secondary structure prediction can aid in the understanding and analysis of protein structure and function. Students will also learn various tools that are used to perform secondary structure prediction.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Secondary Structure Prediction Using Quick2D.
- Perform Secondary Structure Prediction Using Ali2D4.
- Perform Secondary Structure Prediction Using Jpred.
- Perform Secondary Structure Prediction Using HHrepID.
- Perform Secondary Structure Prediction Using DeepCoil.
Section 7: 3D Structure Prediction
Description: This section will make sure students will learn about the principles and methods of predicting the three-dimensional (3D) structure of proteins from their amino acid sequences. This section covers the importance of protein structure in protein function, and how predicting protein structures can aid in the understanding and analysis of protein function, interactions, and drug design. Students will learn about the different methods for predicting protein structure, including comparative modeling, ab initio modeling, and threading. Students will also learn how to use different software tools and databases to perform 3D structure prediction.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform 3D Structure Prediction Using MODELLER.
- Perform 3D Structure Prediction Using SwissModel.
- Perform 3D Structure Prediction Using HHPred.
- Perform 3D Structure Prediction Using M4T.
- Perform 3D Structure Prediction Using IntFold.
- Perform 3D Structure Prediction Using ROBETTA.
- Perform Homology Modeling Using MOE.
Section 8: 3D Structure Visualization
Description: This section will make sure students will learn about the principles and methods of visualizing and analyzing protein structures. Students will learn about the different types of software tools and databases used for 3D structure visualization and analysis, including PyMOL and Chimera. The section covers the use of different visualization techniques, such as surface rendering, ribbon diagrams, and electrostatic potential maps, to highlight different aspects of protein structure and function.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform 3D Structure Visualization Using UCSF Chimera.
- Perform 3D Structure Visualization Using PyMol.
Section 9: 3D Structure Evaluation
Description: This section will make sure students will learn about the principles and methods of evaluating the quality and reliability of protein structures. This section covers the importance of protein structure evaluation in assessing the accuracy and usefulness of predicted or experimentally determined structures, and how it can aid in the interpretation and analysis of structural data. The section covers the use of different software tools and databases for structure evaluation, as well as the impact of various factors on structure quality, such as sequence length, homology, and experimental method.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform 3D Structure Evaluation Using WhatCheck.
- Perform 3D Structure Evaluation Using ProCheck.
- Perform 3D Structure Evaluation Using ERRAT.
- Perform 3D Structure Evaluation Using Verfiy3D.
- Perform 3D Structure Evaluation Using RAMPAGE.
- Perform 3D Structure Evaluation Using SAVES.
- Perform 3D Structure Evaluation Using PROSA.
Section 10: Molecular Docking
Description: This section will make sure students will learn about the different types of docking algorithms and scoring functions used for molecular docking, including rigid-body, flexible, and induced fit docking, as well as the impact of various factors on docking accuracy, such as target and ligand flexibility, solvation, and receptor conformational changes. The section also covers the use of different software tools and databases for molecular docking including
Learning Outcomes: Upon completion of this section, students will be able to:
- Explain Protein-Ligand Docking.
- Perform Protein-Ligand Docking Using MOE.
- Perform Protein-Ligand Docking Using AutoDock Vina.
- Perform Protein-Ligand Docking Using SwissDock.
- Prepare Docking Library of Compounds Using MOE.
- Perform Structure-Based Drug Designing Using MOE.
- Explain Protein-Protein Docking.
- Perform Protein-Protein Docking Using MOE.
- Perform Protein-Protein Docking Using ClusPro.
- Perform Protein-Protein Docking Using PatchDock.
- Predict Peptide Structure Using PEPFOLD3.
- Perform Protein-Protein and Protein-Docking Using Zdock.
- Explain Protein-Peptide Docking.
- Perform Protein-Peptide Docking Using MDockPEP.
- Use Discovery Studio+.
Section 11: Docking Complex Evaluation
Description: This section will make sure students will learn about the assessment of the quality and accuracy of the docking results obtained in the Molecular Docking section, as well as the evaluation of the ADMET properties of potential drug candidates. The evaluation of the docking complex is an essential step in the molecular docking process as it provides insight into the reliability of the predicted binding modes and affinities. Students will learn about different criteria used for the evaluation of docking complexes, including geometric fit, binding energy, and interface properties.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Docking Complex Evaluation Using PDBsum.
- Perform Docking Complex Evaluation Using Pdbepisa.
- Assess the ADMET Properties Using SwissADME.
Section 12: Gene Prediction
Description: This section will make sure students will learn about the computational methods and algorithms used for identifying and predicting genes in DNA sequences. Students will learn about the different types of gene prediction methods, including ab initio, homology-based, and transcriptome-based approaches, and their advantages and limitations. The section also emphasizes the role of machine learning and artificial intelligence techniques in gene prediction and covers various software and tools used in the field, including GeneMark, AUGUSTUS, and GenScan.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Gene Prediction from Eukaryotic Genomes Using GeneMark.
- Perform Gene Prediction from Microbial Genomes Using Prodigal.
- Predict Genes From GeneMonkey Using GenScan.
- Find a Novel Gene Using GenScan.
- Predict Novel Genes in Star Fish or Any Genome Using AUGUSTUS.
Section 13: Protein-Protein Interaction (PPI) Database
Description: This section will make sure students will learn about the fundamental concepts of PPIs, including their significance in cellular processes, disease pathways, and drug discovery. Students will learn about the STRING PPI databases and they will also learn how to perform protein-protein interaction analysis on STRING.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform PPI Using STRING Database.
Section 14: Molecular Dynamics Simulation
Description: This section will make sure students will learn about the fundamental concepts of molecular dynamics simulation, including the equations of motion, force fields, and integration methods. Students will learn about the different types of molecular systems that can be simulated, including proteins, nucleic acids, and small molecules. The section also emphasizes the role of molecular dynamics simulation in understanding the structure and function of biomolecules and covers various software and tools used in the field.
Learning Outcomes: Upon completion of this section, students will be able to:
- Pre-process Protein Structure and Remove Unnecessary Structural Features.
- Construct a Topology File for Simulation Using pdb2gmx.
- Define a Solvant Box for Simulation.
- Perform Solvation (Adding Water Molecules in Solvant Box).
- Generate Input Run File (Replacement of Water Molecules With Ions).
- Replace Water Molecules With Ions Using Genion.
- Perform Energy Minimization.
- Visualize and Analyze the Minimized Structure Using GRACE.
- Perform Equibiliration of Protein Structure NVT ENSEMBLE Phase.
- Perform Equibiliration of Protein Structure NPT ENSEMBLE Phase.
- Execute Simulation Analysis Using mdrun.
Section 15: Biological Programming Using Python, BioPython, R, and BioConductor.
Description: This section will make sure students will learn about programming languages used in bioinformatics, including Python, BioPython, R, and BioConductor. It covers the fundamental concepts of programming, including data structures, control structures, and functions, and provides an introduction to programming languages commonly used in bioinformatics. Students will learn about the basics of Python programming and how to use BioPython to perform common bioinformatics tasks such as sequence alignment, sequence analysis, and database querying. The section also covers the basics of R programming and BioConductor packages that are used in biological data analysis.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Functions Using Bio.Seq Module in BioPython.
- Perform Various Functions Using the SeqRecord Module in BioPython.
- Perform Functions Using the SeqIO Module in BioPython.
- Perform Functions Using the AlignIO Module in BioPython.
- Perform Functions Using the Bio.Blast Module in BioPython.
- Perform Functions Using the Bio.Entrez Module in BioPython.
- Create a Phylogenetic Tree Using the Bio.Phylo Module in BioPython.
- Perform Motif Analysis Using Bio.motifs Module in BioPython.
- Perform Biological Data Manipulation Using R.
- Perform Biological Data Visualization Using ggplot2 in R.
- Utilize Linux Commands for Biological Data Manipulation and Interpretation.
- Perform Microarray Analysis Using R.
- Perform Sequence Alignment Using BioConductor packages.
- Perform Functional Enrichment Using Packages in R Language.
Section 16: Computational Vaccine Designing
Description: This section will make sure students will learn about the different computational methods and tools used in vaccine design, including immunoinformatics, structural vaccinology, and reverse vaccinology. Students will learn about the different steps involved in vaccine design, including antigen identification, epitope prediction, antigen structure determination, and vaccine formulation.
Learning Outcomes: Upon completion of this section, students will be able to:
- Perform Target Identification.
- Use Immunoinformatics Approach for Epitope Prediction.
- Construct the Vaccine Computationally.
- Perform Molecular Dynamics and Immune Simulation.
- Perform Codon Optimization.
- Perform Disulfide Engineering.
- Perform Molecular Docking Between TLR4 and a Protein.
Section 17: In-Depth Introduction to Next-Generation Sequencing, RNA-Sequencing (RNA-Seq), and RNA-Seq Pipeline
Description: This section will make sure students will learn about the principles and applications of next-generation sequencing (NGS) technologies, with a focus on RNA-Seq. The section also covers the different steps involved in RNA-Seq data analysis, including quality control, read mapping, quantification, and differential gene expression analysis. Students will learn about the different bioinformatics tools and pipelines used in RNA-Seq data analysis, such as STAR, HISAT2, StringTie, and DESeq2.
Learning Outcomes: Upon completion of this section, students will be able to:
- Explain NGS and RNA-Seq.
- Describe the RNA-Seq Analysis Pipeline.
- Perform Data Retrieval for RNA-Seq.
- Perform Quality Control Using FastQC.
- Pre-process Raw Reads.
- Perform Alignment of the Reads Against the Reference Genome.
- Perform Post-Alignment Processing.
- Perform Transcript Assembly and Quantification Using StringTie.
- Perform Differential Gene Expression Analysis Using DESEQ2.
- Perform Functional Enrichment Analysis Using enrichR.
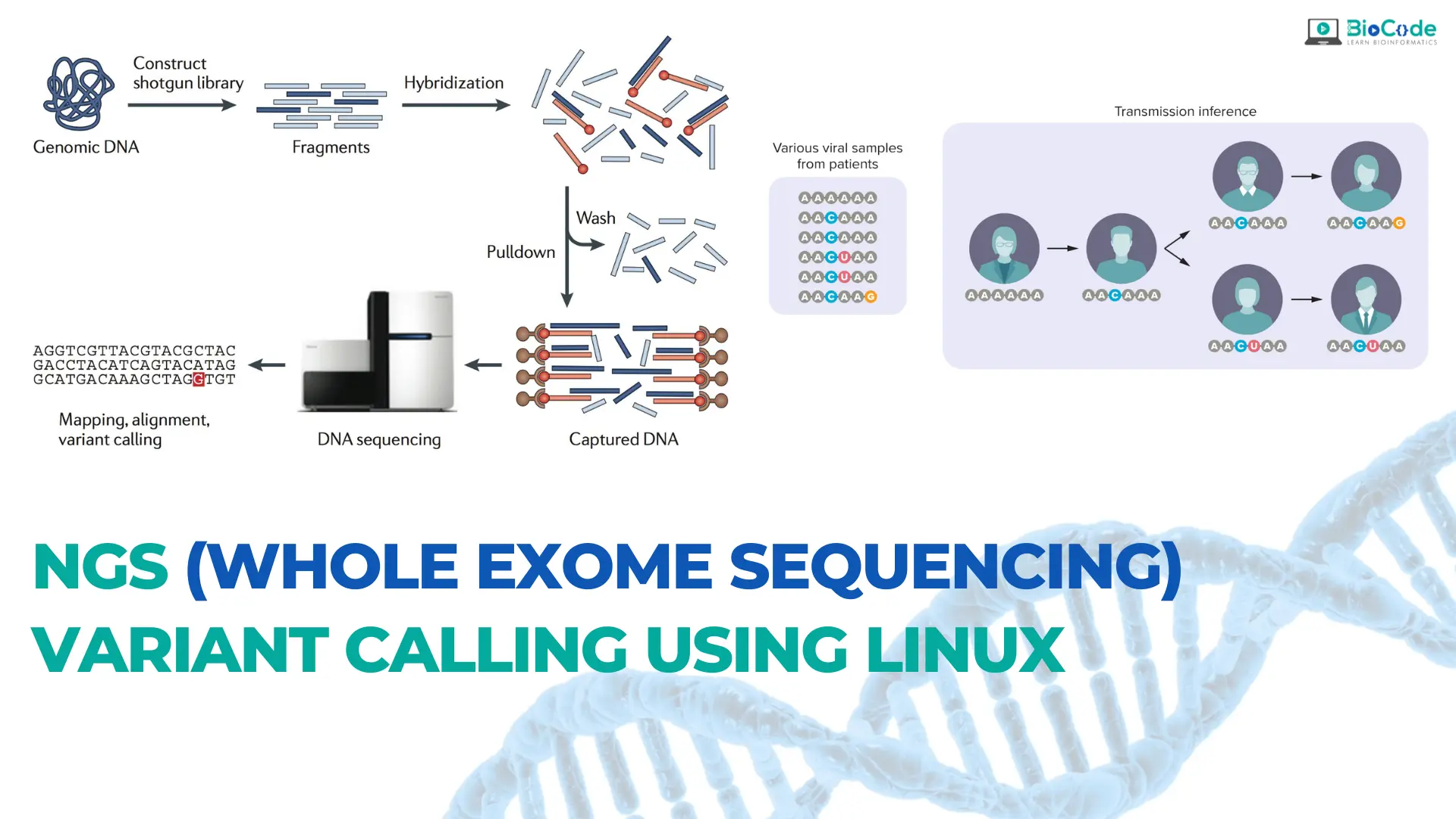
Section 18: Hands-on NGS Whole-Genome Sequencing and Whole-Exome Sequencing Variant Calling.
Description: This section will make sure students will learn about the principles and applications of whole-genome sequencing (WGS) and whole-exome sequencing (WES) technologies. Students will learn about the different types of variant calling, including single-nucleotide polymorphisms (SNPs), insertion/deletions (indels), and structural variants. The section also covers the different steps involved in variant calling, including quality control, read mapping, variant calling, and annotation. Students will learn about the different bioinformatics tools and pipelines used in variant calling and annotation, such as GATK and Samtools.
Learning Outcomes: Upon completion of this section, students will be able to:
- Discuss Next-Generation Sequencing, Whole-Genome Sequencing, and Whole-Exome Sequencing.
- Describe the WGS Variant Calling Pipeline.
- Describe the WES Variant Calling Pipeline.
- Perform WGS Variant Calling.
- Perform WGS Variant Calling for Microbial Genomics.
- Perform WES Variant Calling.
Section 19: In-Depth Introduction to Single Cell RNA-Sequencing (ScRNA-Seq), Pipeline and Single-Cell Technologies
Description: This section will make sure that the students learn about the principles and applications of single-cell RNA sequencing (ScRNA-Seq) technologies. The section also covers the different steps involved in ScRNA-Seq data analysis, including quality control, read mapping, feature counting, normalization, dimensionality reduction, clustering, and cell-type identification. Students will learn about the different bioinformatics tools and pipelines used in ScRNA-Seq data analysis, such as Seurat and ScanPy.
Learning Outcomes: Upon completion of this section, students will be able to:
- Discuss scRNA-seq.
- Explain the Complete end-to-end scRNA-seq Analysis Pipeline.
- Differentiate Between Cellular and Tumor Heterogeneity.
- Differentiate Between Bulk vs. Single Cell RNA-seq Analysis.
- Describe the Single-Cell RNA-seq Technologies.
- Explain the 10x Genomics Complete Pipeline.
- Pre-process the Raw Datasets.
- Identify Cell Sub-populations.
- Perform Normalization, Quality Control, and Dimension Reduction.
- Perform Cell Clustering and Cell Annotation.
- Perform Differential Gene Expression Analysis.
- Perform Downstream Analysis.
- Explain the Seurat Package Complete Guidelines.
- Explain the ScanPy Package Complete Guidelines.

Not ready to enrol?
Get the free syllabus & course updates
We'll email you the full outline for this course plus a starter guide — no spam, unsubscribe anytime.
Tools & technologies you'll use
- Python
- R
- Bioconductor
- Linux
- Conda
- BLAST
- HISAT2
- Samtools
- GATK
- DESeq2
- Seurat
- Scanpy
Free preview — sample these lessons before you enrol
Course Content
Bioinformatics Databases
-
18:02
-
Sequence Analysis
17:59 -
Sequence Retrieval from NCBI
16:17 -
PubMed Central & ENTREZ
11:07 -
GenBank: Nucleotide Database on NCBI
06:50 -
FASTA vs GenBank
18:26 -
Gene Database: A Comprehensive Gene Database
30:21 -
NCBI Genomes & NCBI Assembly: Retrieval of Genomes
36:14 -
RefSeq Database: Retrieval of Single Reference Sequences
11:16 -
BLAST Database Searching
25:37 -
Introduction to Molecular Modeling Database
08:07 -
Database of Short Genetic Variations (dbSNP)
12:16 -
HomoloGene: Discovery of Gene and Protein Families
06:11 -
Taxonomy
09:57 -
Introduction to UCSC Genome Browser & SARS-CoV-2 Viral Genome
13:40 -
Retrieve an Entire Genome & Retrieval of SARS-CoV-2 Viral Genome
09:41 -
Retrieval of Genomic Data & Annotation of SARS-CoV2 Viral Genome
05:30 -
Table Browser & SARS-CoV-2 Viral Genome
12:16 -
Visualization of Genomic Data on the Genome Browser & SARS-CoV-2 Genome
10:51 -
UniProt BLAST – Database Searching
12:33 -
UniProt Peptide Search – Find Regions Within UniProt Database
03:15 -
Introduction to ENSEMBL
07:50 -
Retrieval of a Gene-Protein-Chromosomal Region
18:02 -
Genome Assembly Retrieval and Analysis
10:24 -
Gene Analysis & Annotation
34:40 -
Variation Analysis
24:37 -
ENSEMBL BLAST/BLAT
15:08 -
Regulation – Understand the Influence of Regulatory Elements on Genes
04:19 -
Comparative Genomics Analysis
05:35 -
Introduction to Phytozome
09:39 -
Interpret Plant Genome Records
09:07 -
Download an Entire Plant Genome & Proteome
26:41 -
Keyword or BLAST Search in a Plant Genome
15:58 -
Visualize a Plant Genome Using JBrowse
17:38 -
UniProt Align – Pairwise & Multiple Sequence Alignment and Annotation
03:48 -
UniRef And Retrieve Protein Clusters
11:36 -
UniParc And Find the Non-Redundant Entries
04:59 -
Genome Reference Consortium (GRC)
07:48 -
BioProject
06:40 -
BioSystems
04:16 -
BioSample
02:56 -
Sequence Read Archive (SRA)
07:15 -
Introduction to Gene Expression Omnibus Database
09:16 -
Gene Expression Omnibus – Platforms
05:42 -
Gene Expression Omnibus – Samples
04:16 -
Gene Expression Omnibus – Series
04:01 -
Gene Expression Omnibus – Datasets
04:45
Bioinformatics File Formats
Protein Databases & Analysis
Sequence Alignment & Analysis
Phylogenetic Analysis
Secondary Structure Prediction
3D Structure Prediction
3D Structure Visualization
3D Structure Evaluation
Docking Complex Evaluation
Docking Complex Evaluation
Gene Prediction
PPI Database
Genomics Tools
Molecular Dynamics Simulation
Python
BioPython
R
Linux
R
Target Identification
Immunoinformatics Approach for Epitope Prediction
Computational Construction of the Vaccine
Molecular Dynamics and Immune Simulation
Supplementary 1
Supplementary 2
Supplementary 3
Introduction to NGS, RNA-Seq Pipeline & GALAXY
Practical RNA-Seq Differential Gene Expression Analysis
In-Depth Introduction to RNA-Seq
Genomic Databases for Raw Data
File Formats
Introduction to Linux for RNA-Seq
RNA-Seq Data Analysis Pipeline (Theoretical & Practical)
Basics of Cellular Biology
Genetic Information and Its Flow
Brief Introduction to Genome and Model Organism
Cell Metabolism and Energy Production
Protein Structure, Shape and Characteristics
Chromsomes & Their Characteristics
Evolutionary & Mutation Rates
DNA Replication
PyMol MasterClass: Perform Expert Level 3D Structure Visualization for Drug Discovery
Hands-on: NGS (Whole Genome Sequencing) Variant Calling for Microbial Genomics
Introduction to Anaconda and Jupyter-Notebook for Bioinformatics
Hands-on: Single-Cell RNA-Sequencing Data Analysis Using Python
Hands-on: NGS (Whole Exome Sequencing) Variant Calling Using Linux
Evaluation
Earn a certificate
Add this certificate to your resume to demonstrate your skills & increase your chances of getting noticed.

Student Ratings & Reviews


![Hands-on: Single-Cell RNA-Sequencing Data Analysis Using Command-Line and R [Complete Training]](https://www.biocode.org.uk/wp-content/uploads/2023/02/Course-Thumbnail-for-Hands-on-Single-Cell-RNA-Sequencing-Data-Analysis-Using-Command-Line-and-R.webp)


![Hands-on: Single-Cell RNA-Sequencing Data Analysis Using Python [Complete Training]](https://www.biocode.org.uk/wp-content/uploads/2023/02/Course-Thumbnail-for-Hands-on-Single-Cell-RNA-Sequencing-Data-Analysis-Using-Python.webp)

